
やねうら王は通常のCPU探索以外にディープラーニングを使った思考ルーチンも利用できる。それが「ふかうら王」だ。名前の「ふか」はたぶん「ディープ」から来ているのだろう。
ディープラーニングはCPUでやらせると時間がかかるので、GPUを使うのが普通である。下記の記事では、ROG-STRIX-RTX3090-O24G-GAMINGというGPUカードを使っていて、このカードだけでも価格は20万円を超える。合計約140万円とのこと。恐ろしい世界である。
- “最強PC”を組めるヤツに会いに行く そして生まれた怪物のスペックは:プロ棋士向け最強将棋AIマシンを組む!(1/3 ページ) – ITmedia NEWS
- 広瀬八段、将棋AIマシンで研究スタート 早速優勝も ソフト設定から広瀬流の研究方法まで:プロ棋士向け最強将棋AIマシンを組む!(1/3 ページ) – ITmedia NEWS
将棋専用機に140万もかけるのはプロならではの話で、私のような弱い将棋ファンには強力なGPUがあっても宝のもちぐされである。いつも使っているM1 Macbook Airの内蔵GPUでお手軽に動かせないかと調べていたら、いつのまにか、M1 Mac用のふかうら王がリリースされていた。ありがたい。
- ふかうら王のインストール手順 · yaneurao/YaneuraOu Wiki
- Release Core ML版サンプルビルド20220613 · select766/FukauraOu-CoreML
- MacのCore MLインターフェース by select766 · Pull Request #249 · yaneurao/YaneuraOu(2022/06/13に入ったようだ)
- ふかうら王でMacのCoreMLを使う(成功) – select766’s diary
コンパイルと設定
慣れている人なら、やねうら王添付のドキュメントを読めばコンパイル&設定できますし、コンパイル済のバイナリも公開されています。「評価関数モデルとして、ONNX形式ではなくApple特有のMLModel形式が必要」なのが注意点。
- ふかうら王のインストール手順 · yaneurao/YaneuraOu Wiki
- Release Core ML版サンプルビルド20220613 · select766/FukauraOu-CoreML
エンジン設定はこんな感じにしてみました。ハッシュはもっと大きくしたほうが良いかな? 他の微調整必要だと思うけど、とりあえず載せておきます。
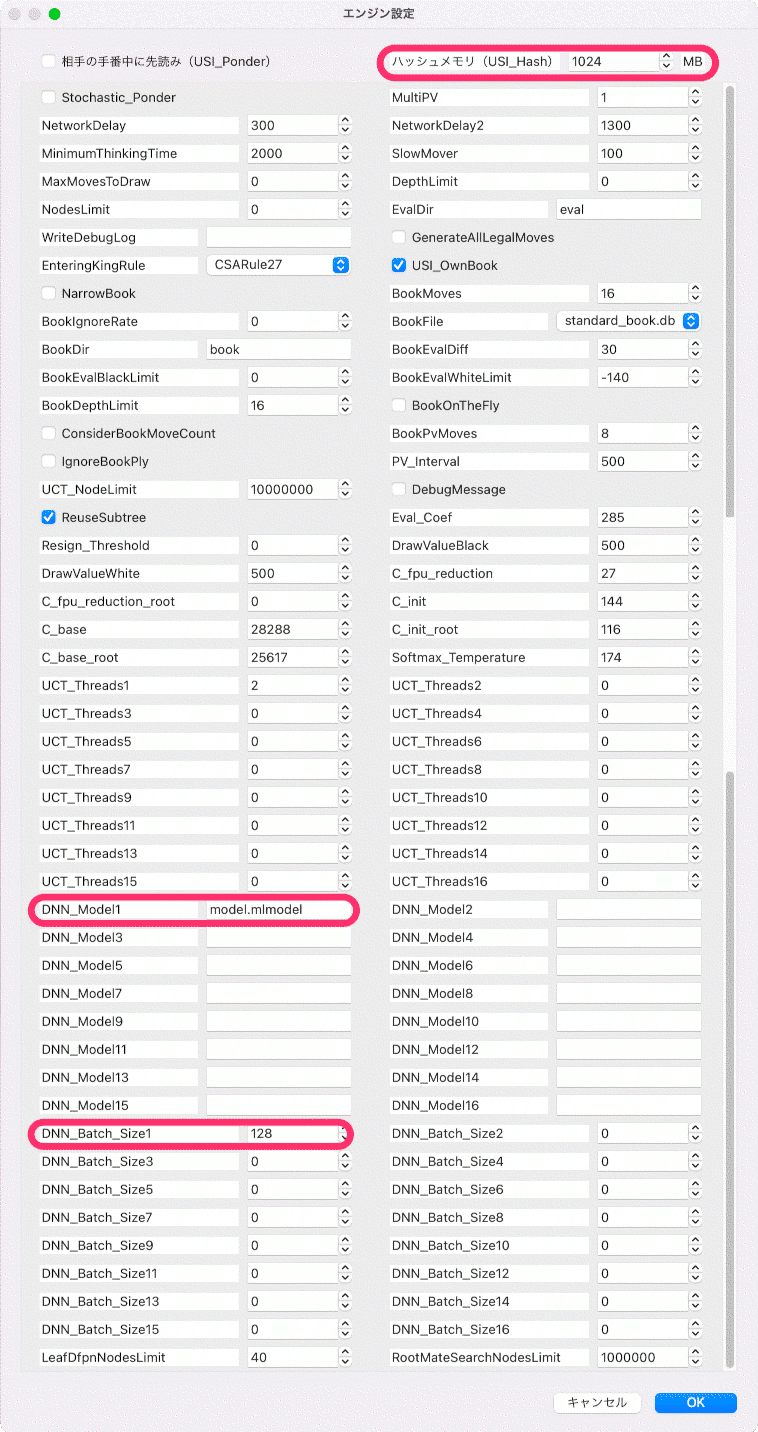
将棋所や諸々の設定は前回記事を参照ください。
速度について
前回と同じく、やねうら王ベンチマークを動かしてみました。秒あたり1300局面ほど調べているようです。M1用ではないバージョンだと71局面/秒なので、格段に速くなっています。素晴らしい。
パッチを作ってくださったselect766さんの記事※1でも1300NPS程度とのことですので、正しく設定できていそう。
(なお、やねうら王とは探索の仕組みが違うので、NPSの直接比較はできません)
$ ./YaneuraOu-by-m1-deep2
bench 128 8 19
info string Start loading the model file, path = eval/model.mlmodel, gpu_id = 0, batch_size = 8
info string Loading already compiled model
info string The model file has been loaded, path = eval/model.mlmodel, gpu_id = 0, batch_size = 8
info string engine forward test. batch_size = 8, Processing time = 861ms.
(中略)
info string engine forward test. batch_size = 8, Processing time = 12ms.
info string All model files have been loaded. 2174ms.
Benchmark
hash : 128
threads : 8
limit : time 19
sfen : default
(中略)
===========================
Total time (ms) : 76217
Nodes visited : 95231
Nodes_visited/second : 1249
===========================
The bench command has completed.
以下はM1パッチが入る前に私がいじっていたバージョンでの測定結果。遅いです。
$ ./YaneuraOu-by-m1-deep
bench 128 8 19
info string Start loading the model file, path = eval/model.onnx, gpu_id = 0, batch_size = 32
2022-08-24 13:24:58.748 YaneuraOu-by-m1-deep[43847:4322204] 2022-08-24 13:24:58.747899 [W:onnxruntime:, helper.cc:61 IsInputSupported] Dynamic shape is not supported for now, for input:input1
info string The model file has been loaded, path = eval/model.onnx, gpu_id = 0, batch_size = 32
info string engine forward test. batch_size = 32, Processing time = 398ms.
(中略)
info string engine forward test. batch_size = 32, Processing time = 385ms.
info string All model files have been loaded. 3155ms.
Benchmark
hash : 128
threads : 8
limit : time 19
sfen : default
(中略)
===========================
Total time (ms) : 88493
Nodes visited : 6287
Nodes_visited/second : 71
===========================
The bench command has completed.
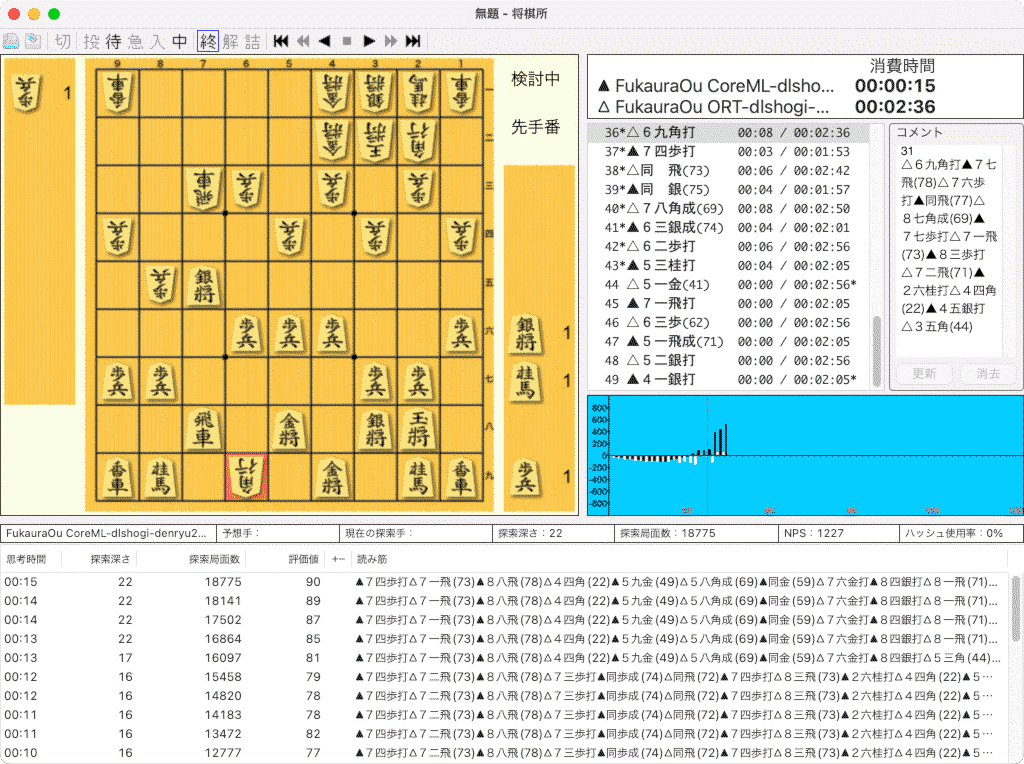
検討中画面。この速度で読めるなら私には充分な強さです。M1 Macbook Airだと検討中にファンが回らないので静かでいいですね。キーボードはちょっと熱くなりますが、さわれないほどではないです。
リンク
- ふかうら王のインストール手順 · yaneurao/YaneuraOu Wiki
- Release Core ML版サンプルビルド20220613 · select766/FukauraOu-CoreML
- MacのCore MLインターフェース by select766 · Pull Request #249 · yaneurao/YaneuraOu(2022/06/13に入ったようだ)
- ふかうら王でMacのCoreMLを使う(成功) – select766’s diary
- M1 Macbook Air でやねうら王を動かしてみた | ず’s 将棋



コメント